
The narration of the article. Click here.
A search engine is an online tool that searches the internet for websites based on the user’s search query.
It uses unique search algorithms to find the results in its own database, sort them, and create an ordered list of these results. This is referred to as a search engine results page (SERP).
Users can use search engines to find content on the internet by using keywords. Despite the fact that a few search engines dominate the market, people can use a variety of search engines. The method by which this ranking is accomplished varies between search engines
Search engines like Google obtain information from a variety of sources, including:
- Websites or web pages,
- User-submitted content, such as that found on Google My Business and Map,
- Online public databases,
- Book scanning and other sources.
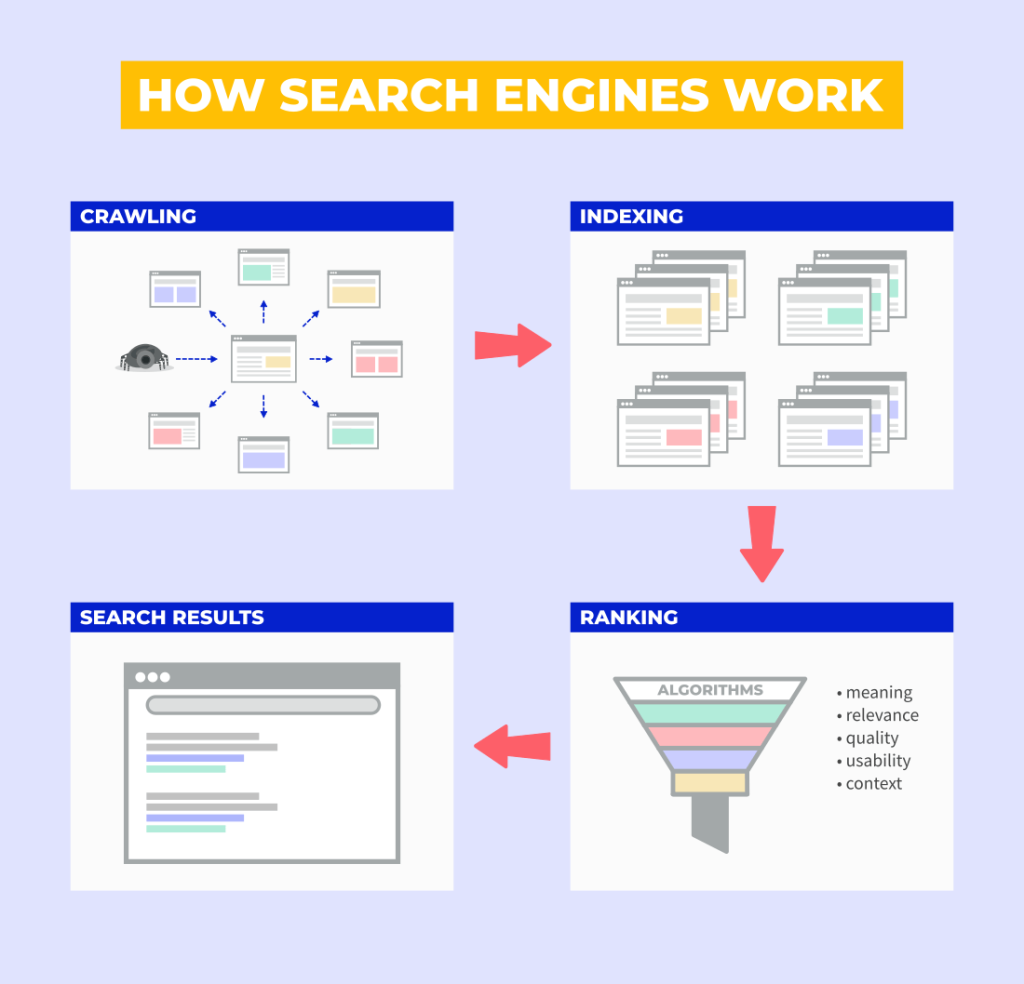
To generate results from web pages, Search engines follow three basic steps:
- CRAWLING :-
Crawling is the process by which search engines discover new and updated web content, such as new sites or pages, changes to existing sites, and dead links.
To accomplish this, a search engine employs a programme known as a ‘crawler,’ ‘bot,’ or ‘spider’, which employs an algorithmic process to determine which sites to crawl and how frequently.
As a search engine’s crawler moves through your site,
- It will detect and record any links on the pages,
- Adding them to a list that will be crawled later.
This is how new content is found. If you use a managed web host, such as Wix or Blogger, they may request that search engine crawl any updated or new pages you create.

The following are some common methods for search engines to crawl a page:
- Link extraction from an existing page:
Crawlers can read data from existing pages, and when these pages are crawled again, they automatically reach your new links if they are present in your existing domain.
For example, if you have a newly written blog linked to a previously indexed blog, the search engines will automatically crawl the new blog.
- Sitemaps
This is yet another method for submitting a group of URLs on your domain to search engines, which will then crawls them automatically.
- Submission of a Page
Simply submit you’re newly created page to Webmaster Tools such as Google Search Console, Bing Webmaster Tool, and so on, and it will be crawled by the Search Engines.
Keep the following in mind when constructing a page:
- Submit and include all URLs that need to be crawled and indexed in the robots.txt file,
- Use directives like nofollow and rel = canonical with caution.
- Examine your pages for thin and low-quality content.
- INDEXING :-
When a page is discovered, search engines say Google attempts to determine what the page is about, this is the process of indexing. Google analyses the page’s content, catalogs images and video files embedded on the page, and otherwise attempts to understand the page. This data is saved in the Google index, a massive database stored on Supercomputers.
The following signals are used by search engines to discover a page:
- Examine the keywords on the page.
- The type of content (representation) crawled
- How frequently or recently is the page updated?
- Previous user interaction with the page or domain
The goal of indexing, a page is to provide information to the seeker with relevant information to their search intent.

To improve your page indexing, do the following:
- Make meaningful page titles that are short and to the point.
- Use page headings that convey the page’s subject.
- To convey information, use both text and images.
Search engines can understand some images and videos, but not as well as text. At the very least, annotate your video and images with alt text and other appropriate attributes.
- SERVING AND RANKING :-
When a keyword is entered into a search box, search engines look for pages in their index that are a close match; a score is assigned to these pages based on an algorithm that includes hundreds of different ranking signals. These pages (or images and videos) will then be presented to the user in descending order of score.
So, in order for your site to rank well in search results pages, you must ensure that search engines can crawl and index your site correctly – otherwise, they will be unable to rank your website’s content appropriately in search results.
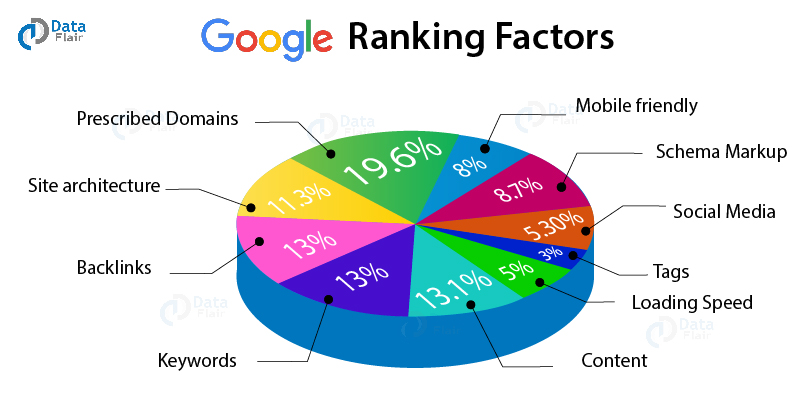
To improve you’re serving and ranking, do the following:
- Make your page mobile-friendly and quick to load,
- Maintain your page’s useful content and keep it up to date,
- Back links,
- Page Speed for Engagement.
Search Engines like Google employs human Search Quality Raters to test and refine the algorithms to ensure that they are performing properly. This is one of the few occasions when humans, rather than programmes, are involved in the operation of search engines.
FINAL SAY
It is easier to create crawlable and indexable websites once you understand how search engines work. Sending the right signals to search engines ensures that your pages appear in relevant results pages for your business. Serving up the content that searchers and search engines want is a step toward building a successful online business.
Hope this article helped you, if so then please do like, share and comment.
P.S going to publish SCO for beginners soon, Subscribe now for new posts like this.
Thank you and have a nice day !
